眼见未必为实:AI 生成内容引发的信任危机
最近,相信不少朋友在刷手机的时候,都被这样一组图片给惊到了。马斯克居然在抖音直播间带货老干妈,苹果库克转身就入职了小米汽车,甚至连小学生在小卖部买零食的场景都做得有鼻子有眼。这些图片在社交平台上疯狂刷屏,乍一看细节逼真,光影完美,几乎让人难辨真伪。
技术狂飙背后的 AIGC 浪潮
这可不是什么简单的 PS 恶搞,而是人工智能生成内容(AIGC)技术迭代的直接体现。现在的 AI 绘图工具,早就不是当年那个画手画脚都困难的水平了。它们能够精准理解语义,生成符合逻辑的光影和纹理,甚至连皮肤的质感、背景的虚化都能处理得滴水不漏。说白了,技术门槛的降低让造假变得前所未有的容易。
“后真相”时代的三大风险
当图片不再代表真相,我们面临的挑战是巨大的,主要体现在以下几个方面:
1. 虚假新闻泛滥:别有用心的人可能利用该技术制造谣言,诽谤公众人物甚至操纵舆论。
2. 甄别成本上升:对于普通用户而言,信息真伪的判断难度急剧增加,信任成本变高。
3. 认知体系颠覆:传统的“眼见为实”观念正在被彻底打破,社会信任体系受到冲击。
构建防御机制:技术与法律的双管齐下
面对这股浪潮,我们不能因噎废食,但必须保持警惕。一方面,平台需要加强内容审核机制,利用 AI 技术来对抗 AI 生成内容,添加数字水印标识;另一方面,法律法规也得跟上,明确生成式内容的边界和责任。作为用户,咱们也得培养媒介素养,保持理性判断,不轻信、不盲传。毕竟,在真假难辨的数字世界里,保持清醒的头脑才是最重要的护城河。

OpenAI 放大招:ChatGPT Images 2.0 如何让图片生成变得“会思考”?
最近科技圈又炸锅了,美国人工智能巨头 OpenAI 正式推出了ChatGPT Images 2.0 模型。这可是 ChatGPT 平台图像生成功能的一次重磅升级。虽说现在 AI 画图已经不算新鲜事,但这次 OpenAI 搞出了点不一样的花样,直接让 AI 学会了“先思考,后动手”。
不再是“盲画”,AI 学会了先思考后动手
以前的 AI 画图,更像是拿到指令就埋头苦干,有时候画出来的东西逻辑不通。但这次的 Images 2.0 被官方称为首个具备“思考”能力的图像模型。啥意思呢?就是用户在生成图片前,系统会先对图像结构进行推理规划。更厉害的是,它还能联网检索信息,自动把品牌 logo、场景细节这些容易出错的地方给补全了。这就好比以前是让你闭着眼画画,现在是允许你先查查资料再动笔,成品的真实感自然上了好几个台阶。
每周 10 亿张的背后,是技术能力的全面跃升
数据不会说谎,目前 ChatGPT 每周的图像产出量已经超过了10 亿张。这么大的用量背后,是模型能力的硬核实升级。具体来说,这次更新主要在几个方面有了巨大进步:
1. 指令遵循更精准:你说啥它画啥,不再经常性“耳背”。
真假难辨的困扰,我们该如何应对?
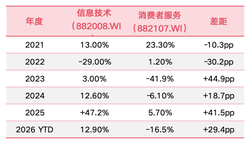
技术越强,责任越大。最近社交媒体上热传的那些“马斯克带货”、“小学生选零食”、“库克入职小米”的图片,看着跟真的一样,其实都是这个模型生成的。因为画面细节过于逼真,相关话题迅速冲上热搜,引发了全网热议。特别是“库克入职小米”那张假图,传播太广误导性太强,逼得小米高管不得不亲自出面辟谣。这也给我们提了个醒,眼见未必为实,在 AI 生成的内容面前,咱们得多留个心眼。
总的来说,ChatGPT Images 2.0 的发布确实是技术的一大步,让创作变得更简单、更高效。但同时也带来了信息真实性的新挑战。技术本身是把双刃剑,怎么用得好、管理规范跟得上,才是接下来大家最需要关注的重点。
技术迭代的新里程碑:ChatGPT Images 2.0 深度解析
从此次升级的核心亮点来看,新一代模型展现出了与众不同的技术突破。与市场上现有的其他图像生成模型相比,ChatGPT Images 2.0 最显著的区别在于其近乎完美的真实感,这标志着 AI 生成内容正在迈入一个全新的阶段。
去除 AI 痕迹,还原真实质感
在过去的 AI 生成内容中,我们常常能捕捉到一些不自然的细节,比如光影的违和或纹理的模糊。但这次升级几乎去除了所有可识别的 AI 痕迹。生成的照片在细节处理上呈现出极强的真实感,无论是物体边缘还是背景融合,都让人难以分辨真伪,极大地提升了用户体验。
文字处理与思维能力的跃升
除了视觉层面的突破,模型在认知层面也迎来了显著提升。文字处理能力更强,甚至能够像人类一样思考。这意味着模型不仅能精准理解复杂的指令,还能在生成过程中融入更深层次的逻辑推理,使得输出结果更符合人类的直觉与预期。
媒体实测验证升级成效
模型发布后,业界媒体迅速行动以验证其实际表现。蓝鲸新闻记者对 ChatGPT Images 2.0 进行了深度实测,通过一系列严苛的测试场景,进一步确认了该模型在实际应用中的稳定性与潜力,为后续的行业应用提供了有力的参考依据。

咱们先来聊聊这次针对 AI 图像生成模型的深度实测,毕竟现在市面上号称能画图的工具不少,但真正能经得起推敲的才是硬实力。这次测试的核心焦点非常明确,就是画面精度与语义理解的完美结合,记者直接给模型出了个难题,想看看 Images 2.0 到底有几斤几两。
首轮测试:画面精度与品牌元素的融合
记者输入的提示词相当具体,要求生成一张“马斯克带货蓝鲸新闻”的图片。这不仅仅是要画个人,还得把特定的品牌元素和文字信息完美嵌进去。结果让人眼前一亮,短短不到一分钟,Images 2.0 便迅速交出了答卷。画面里的马斯克身穿黑色 T 恤,神态自然,更厉害的是四周布满了蓝鲸新闻的品牌元素,甚至连“独到视角、价值新闻”这种补充性的品牌关键词都清晰可见。整体构图自然、细节丰富,几乎让人难以分辨是否为 AI 生成,这对于很多模型来说都是个容易翻车的细节点。
二轮测试:复杂场景的还原能力
紧接着,记者又加大了难度,尝试使用“山姆·奥特曼在直播间带货”的提示词进行生成。直播间是个复杂场景,涉及光影、人物姿态以及背景的商业氛围。短时间内,Images 2.0 同样给出了一幅以假乱真的图片。这不仅证明了模型在人物面部还原上的稳定性,更展示了其在复杂场景光线处理和逻辑布局上的深厚功底。
技术总结:AI 生成能力的实质性突破
通过这两轮高密度的测试,咱们能明显感觉到,现在的 AI 图像生成技术已经不再是简单的“拼凑素材”。从文字渲染到人物神态,再到品牌元素的无缝植入,Images 2.0 展现出了极高的成熟度。这种级别的生成能力,意味着未来在商业宣传、内容创作等领域,AI 将能提供更加可靠且高效的视觉解决方案,确实有点东西。
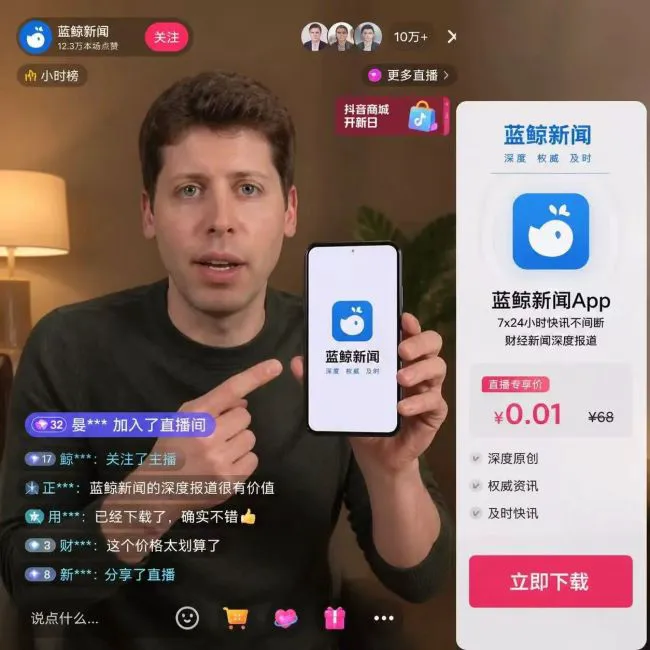
AI 造假逼真度:几乎无法区分的“真实”直播间
咱们先得聊聊这张图给人的第一冲击。这画面可不是随便画画的,它完整复现了直播间的典型布局。你仔细看左上角,那是“蓝鲸新闻”的官方账号,粉丝数和点赞量直接显示"10 万+",细节满满。
再看主播的位置,虽然是个虚拟的山姆·奥特曼形象,但神态、光影跟真人直播没什么两样。这还不是全部,那些补充元素也近乎完美:
1. “深度权威及时”的品牌标语赫然在列。
2. "7x24 小时快讯不间断”的功能介绍也安排上了。
3. 就连售价 0.01 元的“直播专享价”商品链接,以及网民评论的文字都能精准呈现。
说句实在话,这整体观感跟真实直播间截图放在一起,几乎无法区分。
Images 2.0 的核心突破:不只是画图,更是“思考”
一分钟做海报、画漫画,Images 2.0 这是要来抢人类饭碗了?其实对于 Images 2.0 来说,画面精度升级只是最基础的操作,其最大的突破在于增加了“思考”能力。
从上面提到的那些补充信息就能看出来,记者当时仅仅输入了一句关键词。模型可不是瞎画,它能主动联网搜索已有信息,对画面进行补充与完善。这就好比它不仅有一双手,还有一个会查资料的大脑。
实测验证:效率与深度的双重碾压
为了进一步验证模型的思考能力,记者进行了更深度的测试。这次的任务是生成一张宣传海报,提示词是“蓝鲸新闻参加北京车展”。
结果怎么样?不到一分钟,Images 2.0 便交出了一张要素丰富的图片。这速度,这质量,确实让人不得不对 AI 的生产力刮目相看。

AI 绘图实测深度解析:从车展海报到新闻漫画,模型能力到底几何?
咱们先来聊聊这次实测的核心画面。主体定调为"2026 北京国际汽车展览会”,地点锁定在中国国际展览中心,标语也没落下,“现场直击、深度报道、洞察趋势”这些品牌元素都安排上了。整体来看,风格正式,信息层级也清晰,乍一看挺像那么回事。
细节里的“时间陷阱”:模型逻辑仍需打磨
但美中不足的地方也得实话实说。模型初次生成时,居然把年份错写成了"2024 年”。这可是个硬伤,毕竟主题是 2026 年的展会。经记者再次提示纠正后,模型才把时间修正为"2026 年”。这一细节反映出,尽管模型具备一定的推理与检索能力,但在时间逻辑的自洽性上仍有提升空间。 这说明 AI 在处理具体时空信息时,还不够严谨,容易出现“幻觉”。具体表现在:
1. 初始推理偏差:模型未能直接匹配未来年份与展会主题。
2. 修正依赖提示:需要人工干预才能实现逻辑自洽。
3. 时间敏感度不足:对数字信息的精确性把控有待加强。
多模态叙事进阶:漫画生成的惊喜
除了海报,记者还让模型生成了一组以蓝鲸新闻为主题的漫画。这一次,Images 2.0 展现了它在多模态叙事上更强的思考能力。相比之下,漫画生成不仅考验画图,更考验对新闻内容的理解和情节编排。这表明 AI 模型正在从单纯的图像生成,向更深层次的内容理解与叙事表达迈进。
总的来说,这次实测让我们看到了 AI 模型的进步,也明确了接下来的优化方向。对于用户而言,既要善用工具的效率,也要保持对关键信息的审核力度。 随着技术的迭代,相信这些问题会逐渐得到解决。

咱们先来聊聊最近 AI 绘图领域的一个大新闻。大家看到的这组图片,完全是由 AI 生成的,而且整个漫画足足有 6 格,画风统一,剧情连贯,这在以前可不是件容易事儿。
漫画案例深度解析
整组漫画不仅角色形象前后一致,比如那个蓝鲸标志和记者造型,从头到尾都没走样。更厉害的是,对话框里的中文文字渲染得清晰准确,幽默感和叙事逻辑也都在线。这说明什么?说明Images 2.0 已经从单张“造图”进化到了能够理解并执行完整短剧分镜的水平。
行业冲击与替代风险
可以说,Images 2.0 已经在直接挑战设计师与漫画家的“饭碗”了。那些过去高度依赖人工完成的创意排版、海报绘制和多格漫画工作,正面临被 AI 快速替代的风险。这可不是危言耸听,技术迭代的速度超乎想象。
核心技术跨越升级
总结来看,ChatGPT Images 2.0 在多个维度实现了跨越式升级,咱们可以重点看看这几个方面:
- 像素级精度:小字号文本、图标、UI 元素等复杂细节可一键生成,再也不用担心细节模糊。
- 多语言渲染质变:中文等文字得以精准呈现,通篇默写《出师表》也不在话下,语言障碍基本被扫清。
- 视觉风格成熟:从照片级逼真感到电影剧照、动漫漫画,都能拿捏得当,风格切换自如。
- 具备推理能力:更为关键的是,它成为首个具备推理能力的图像模型,能够主动联网搜索、自我复核输出,聪明程度上了一个大台阶。
这一系列升级,标志着 AI 绘图不再是简单的玩具,而是成为了真正能干活的生产力工具。

技术光环下的阴影:AI 生成内容的标识缺失
咱们得客观地说,虽然现在的 AI 模型技术突飞猛进,但还真不是十全十美的。记者经过一番实测后发现了一个挺关键的问题:Images 2.0 生成的所有直出图中,均没有标注"AI 生成”的强制水印。 这一点看似是技术细节的疏忽,实则可能引发连锁反应。
虚假新闻滋生的温床
这种水印的缺失,直接导致了当前网络生态中出现了一些令人担忧的现象。具体来说,主要体现在以下几个方面:
1. 造谣门槛大幅降低: 造谣者可以轻易拿来这些无水印图片制作虚假新闻,无需任何技术处理。
2. 信息传播风险增加: 缺乏标识的图片更容易被当作真实证据在社交网络上传播,误导公众。
3. 监管与溯源困难: 一旦虚假信息扩散,后续想要追踪源头和辟谣的难度将呈指数级上升。
人类辨识能力的严峻挑战
随着 Images 2.0 生成的图片越来越逼真,人类分辨真假的难度也在同步上升。 这不仅仅是一个技术问题,更是一个社会信任问题。当“眼见为实”不再可靠,我们需要建立新的机制来应对这场真实性危机,否则网络环境的公信力将受到严重侵蚀。